What is sampling-event data?
Sampling-event data describes species occurrences in time and space together with details of sampling effort. Such data is available from thousands of environmental, ecological, and natural resource investigations. These can be one-off studies or monitoring programmes. Such data are usually quantitative, calibrated, and follow certain protocols so that changes and trends of populations can be detected. This is in contrast to opportunistic observation and collection data, which today form a significant proportion of openly accessible biodiversity data.
What is data publishing?
In the context of GBIF, ‘publishing biodiversity data’ is the process through which biodiversity datasets are made publicly accessible in a standardized format, via an online access point. Publishing the data following international standards enables integration of the data into GBIF.org where published datasets can then be discovered and accessed via the global GBIF.org website and associated web services thereby making it easily accessible by taxon, region, time period and other criteria.
What difference does sharing sampling-event data make?
Whether from one-off studies or monitoring programmes, data from sampling-event data are highly valuable for research and global policy applications. Data from systematic monitoring schemes, which harvests species data from a given set of sites repeatedly over time using a well-defined sampling effort, open the door to key ecological analyses including population and metapopulation ecology, phenology studies, community ecology and other biodiversity disciplines. Changes in community structure and other metrics enable a range of Essential Biodiversity Variables EBVs.
Who should be interested?
Scientists
A number of ecology disciplines and their analytical methods require quantitative data to produce meaningful results. Ecology is a cutting edge biodiversity discipline which is increasingly dependent on quantitative data. Data on the relative abundance of species at any scale is an essential component for understanding the spatiotemporal structure of biodiversity and its dynamics.
Policy makers
A number of Essential Biodiversity Variables (EBVs), such as species distribution and population abundance belonging to the Species Populations EBV class, are dependent on the availability of globally aggregated and formatted sampling-event data. The EBVs will directly influence evidence-based decision making, meaning every record shared using the sampling-event data format can be used for global good.
How do I go about sharing sampling-event data?
Use the GBIF Integrated Publishing Toolkit (IPT) to share your sampling-event data. For guidance, follow this how-to guide. For additional guidance, refer to the best practice guide for publishing sampling-event data
How does it fit together with other types of data inside and outside GBIF?
GBIF supports sharing biodiversity data at four varying levels of richness (data types):
-
Resource metadata – structured information about the dataset, without any data
-
Checklist data – lists of species belonging to some category (e.g. taxonomic, geographic, trait-based, red list, crop wild relatives).
-
Occurrence data – lists of species occurring at a particular place and normally on a specified date.
-
Sampling event data — lists of collecting events and their observed species, together with data on sampling methods and often with quantitative information, i.e. with documented sampling effort.
The richer the data is - the more complete answers is has to the ‘five Ws’:
-
What collecting event happened?
-
Who carried out the sampling?
-
When did the event start and end?
-
Where did the event take place? What space were sampled?
-
Why did the sampling happen?
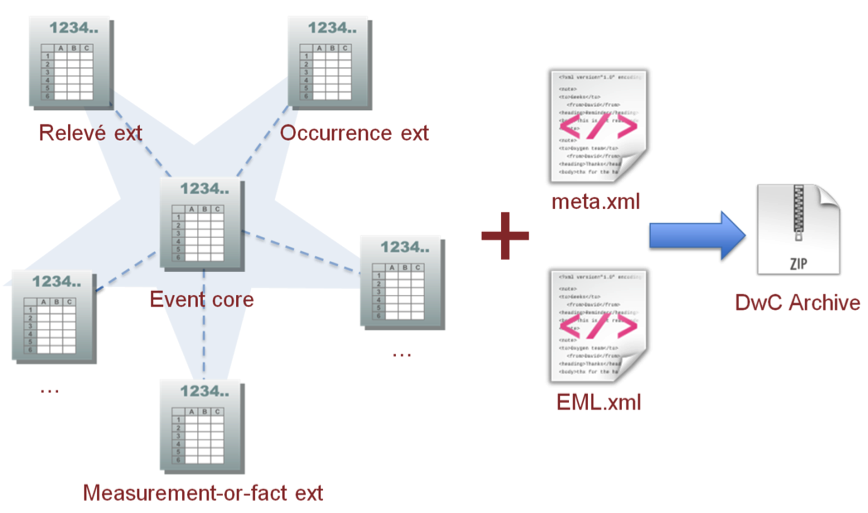
What does it look like?
Below is a simplified picture of the sampling-event data format structure. The format is explained in depth in the best practice guide for sampling-event data. The IPT how-to publish guide lists a number of exemplar sampling-event datasets.